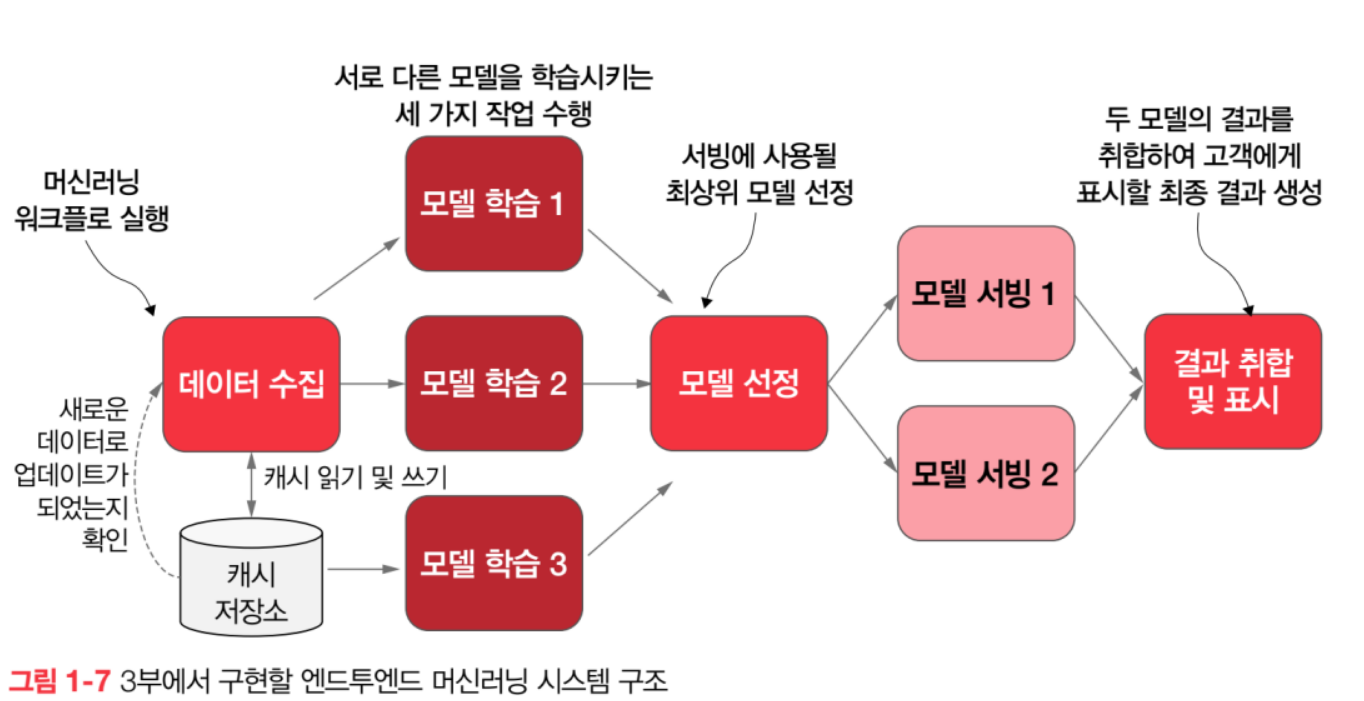
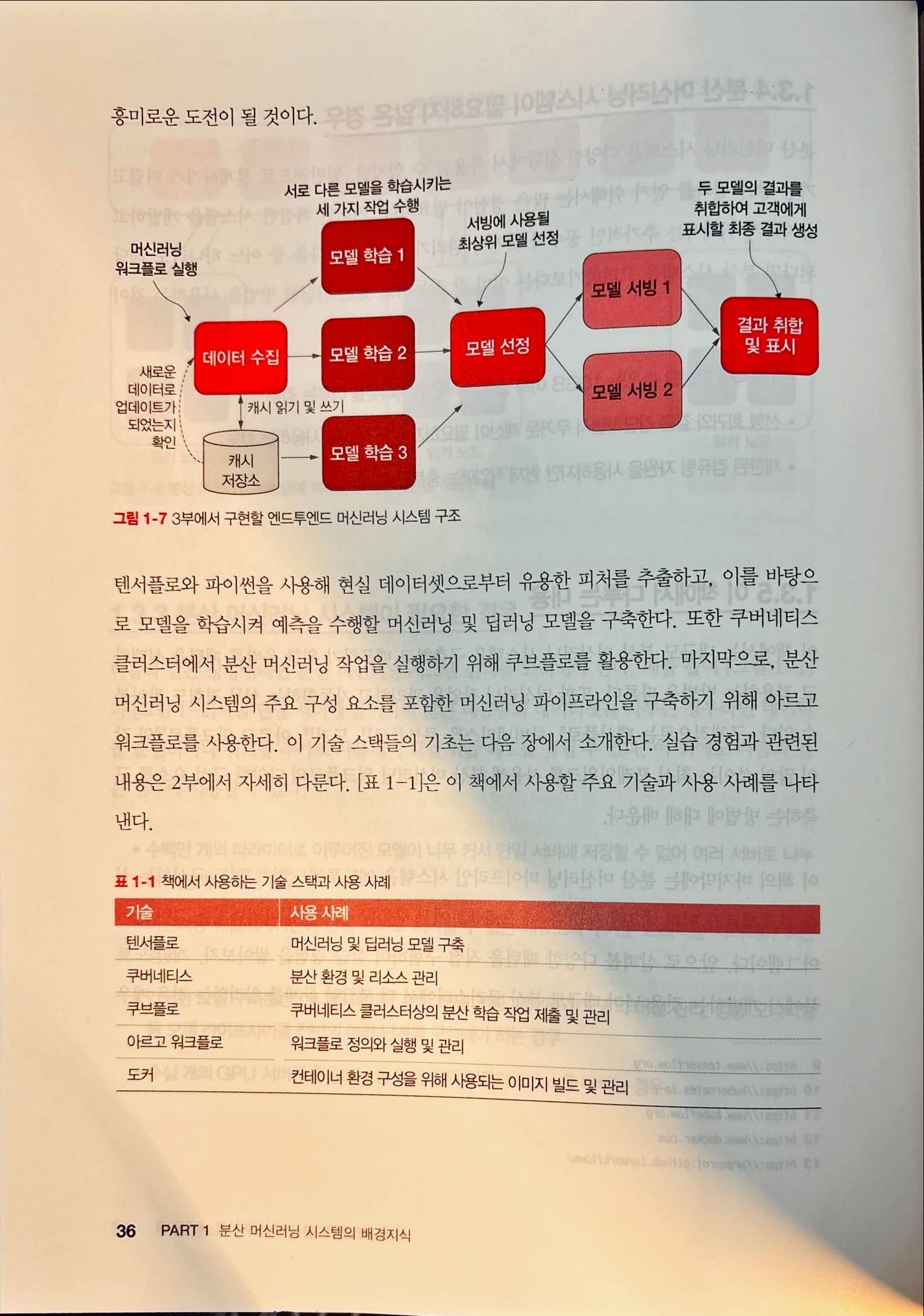
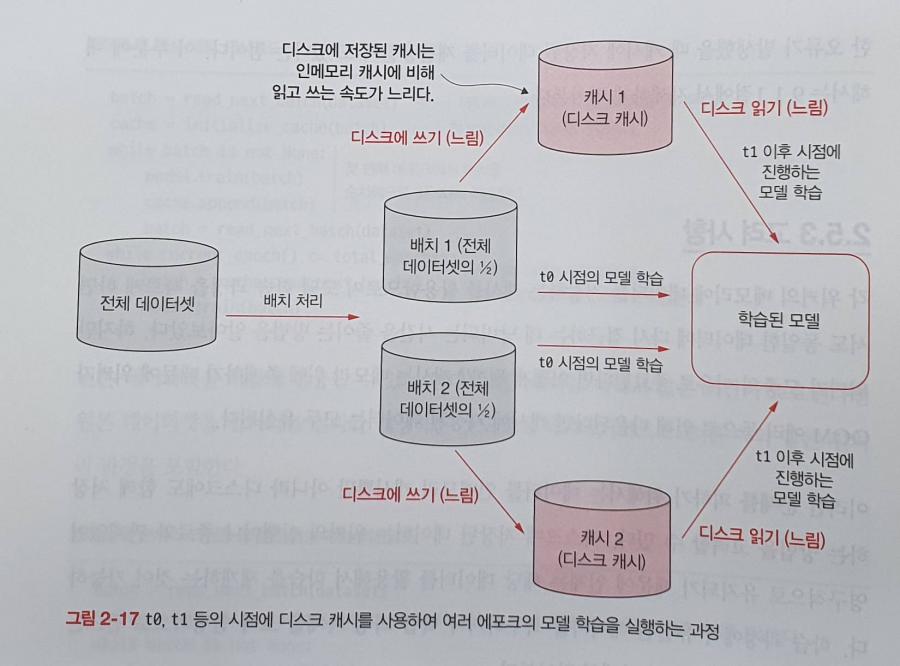
대규모 머신러닝 시스템 디자인 패턴 책을 읽었다. 대규모 머신러닝에 대한 설계 및 각종 디자인 패턴을 소개하는 책이었다.
몇 가지 패턴 중, 흥미가 생기는 패턴을 찾아 읽어 보았다. 먼저 데이터 수집 패턴이었다. 우리에게 데이터셋이 있고, 이를 활용해 머신러닝 시스템을 구축한다고 생각할 때, 먼저 해야 할일은 무엇일까? 데이터셋을 잘 이해하는 것이다. 데이터 수집에는 배치 방식과 스트리밍 방식이 있는데 스트리밍 방식은 데이터의 양이 지속적으로 증가할 때 사용이 되고, 배치 방식은 고정된 데이터 양에 사용이 된다고 한다.
2장에선 주로 배치 방식의 데이터 수집에 대해 다루고 있으며, 스트리밍 방식에도 배치와 동일한 패턴이 사용될 수 있다고 한다.
여기선 배치 처리 패턴과 그에 관련되어 샤딩 패턴을 소개하고 있었다. 그리고 데이터를 재활용하기 위한 캐싱 패턴이 소개되고 있었다.
다음으로 3장에선, 분산 학습 패턴에 대해 소개하고 있었다. 데이터 수집을 완료했다면 다음은 분산 학습인 것이다. 분산 학습이란 데이터 수집 과정에서 처리된 데이터를 가져와 모델을 초기화 한 뒤, 여러 대의 서버로 구성된 분산 환경에서 모델을 학습시키는 과정이라고 한다. 네트워크의 경우 인피니밴드 또는 RDMA를 사용한다고 한다. 이 책에선 이후 LesNet 모델을 사용해 CNN학습을 분산 학습을 통해 진행하는 예시를 들고 있었다.
4장에선 학습이 완료된 모델을 서빙에 활용하는 모델 서빙 패턴을 소개하고 있었고, 5장에선 워크플로 패턴이라 하여 머신러닝 시스템 내의 다른 구성 요소를 모두 연결하는 필수 요소에 대해 소개하고 있었다. 단순하게는 데이터 수집, 모델 학습, 모델 서빙 과정을 연결하는 간단한 구현이 될 수도 있지만 현실 세계에서 발생하는 다양한 시나리오와 요구 사항에 대응하고 성능을 최적화하기 위한 복잡한 구조를 가지는 것도 가능하다고 한다.
워크플로는 머신러닝 시스템 내의 구성 요소를 인드투엔드(end-to-end)로 연결하는 프로세스라고 한다. 워크플로가 복잡해 지면 순차 워크 플로와 DAG로 크게 나뉠 수 있다고 한다. DAG는 각 단계가 순환 고리를 가질 수 있는지 확인하고 순환 고리를 제거하는 작업을 거쳐야 한다고 한다.
이후 복잡한 머신러닝 워크플로를 체계화 하는 팬인 및 팬아웃 패턴과 동기 및 비동기 패턴을 소개한다. 팬인 및 팬아웃 패턴은 머신러닝 시스템의 복잡한 요구 사항을 거의 대부분 해결할 수 있다고 한다. 동기 및 비동기 패턴은 학습이 오래 걸리는 한 모델로 인해 전체 워크플로의 수행 시간이 길어지는 것을 방지할 수 있다고 한다. 빨리 학습이 완료된 모델은 바로 서빙에 투입해서 사용자 요청에 응답하고, 그와 동시에 학습 시간이 긴 모델은 서비스에 영향을 주지 않으면서 계속 학습을 진행하는 형태이다.
이후엔, 뒷장에서 운영 패턴과 실습을 하는 내용이 소개되고 있다.
이 책에선 크게 14가지의 분류로 대규모 데이터 처리와 분석을 위한 분산 머신러닝 실무 가이드를 제시하는 머신러닝 패턴을 소개하고 있으니 머신러닝에 종사하는 분들이 읽어 보시면 좋은 내용이 많이 있으리라 생각이 들었다.
이 글은 한빛미디어로 부터 책을 증정받아 작성되었습니다.