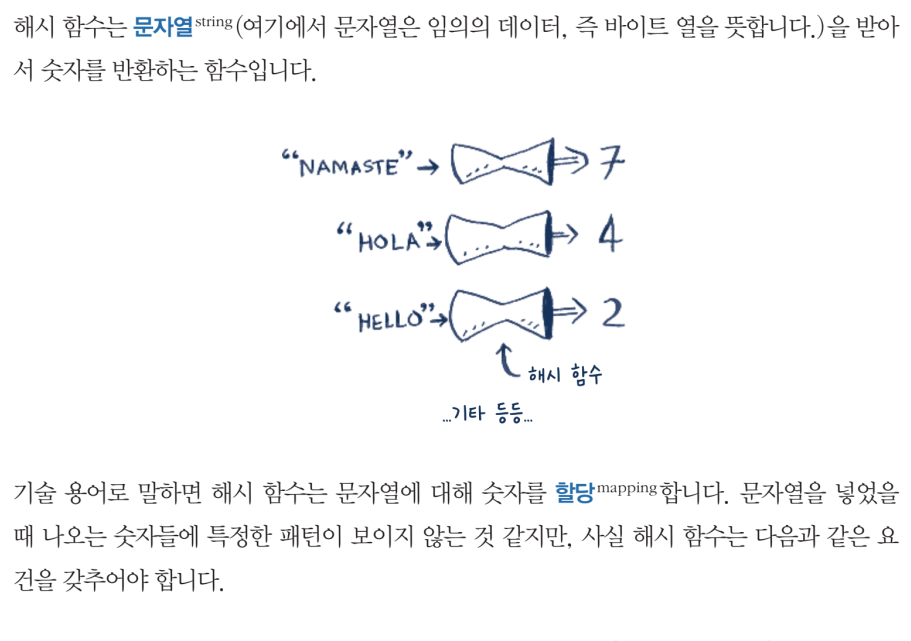
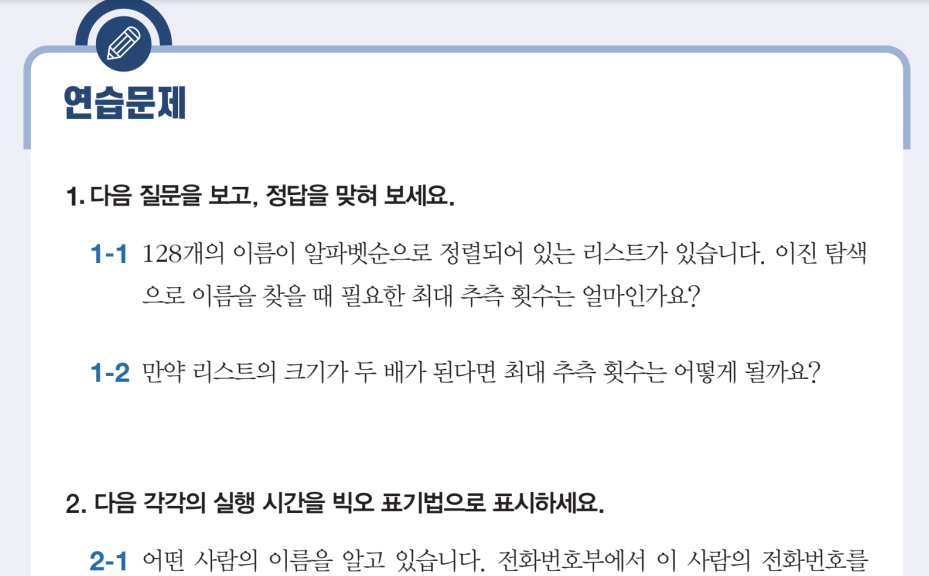
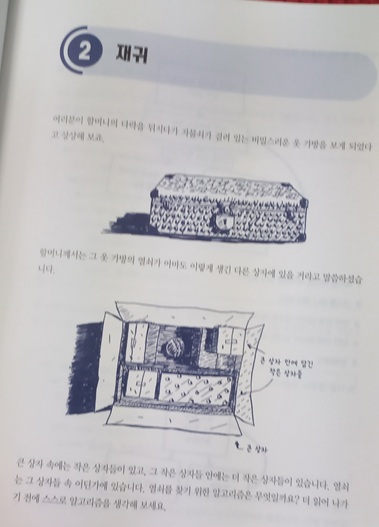
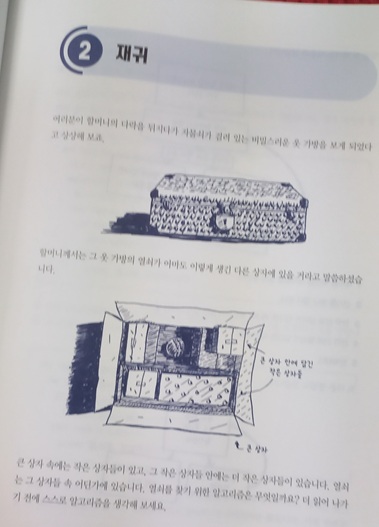
솔직히 기존까지 알고리즘 공부를 많이 해봤지만, 매번 기억에 남는 것은 하나도 없었다. 이 책의 제목과 표지만을 봤을 때 조금 달랐던 점은, 자바 또는 파이썬 코드 위주의 알고리즘 문제 풀이 서적과 다르게 어떻게든 이해시키려고 노력한다는 것이었다. 정의를 먼저 소개하고 활용법을 제시하기보다 문제 상황을 먼저 던진 다음, 이런 경우라면 어떻게 해결할 수 있겠는가? 라는 질문으로부터 출발하는 방식이 매우 마음에 들었다.
여기서 간단히 내가 회사에서 하는 업무를 소개하자면, Elasticsearch/OpenSearch와 같은 검색엔진 클러스터를 구축 및 관리하는 역할로 파면 팔수록 Computer Science적 지식을 필요로 하는 분야다. (깊게 들어가면 사실 그렇지 않은 분야가 있겠냐만은..) 아래 두 가지 특징을 살펴보면, 왜 자료구조와 알고리즘 지식이 뒷받침되어야 하는지 알 수 있다.
1. Heap
- C/C++의 Pointer의 개념이 없는 Java에도 여전히 객체의 참조는 관리해야 하므로, 객체 저장소인 heap 관리 역할의 OOP(ordinary object pointers)라는 자료구조가 존재한다. 32bit 시스템(ILP32)에서 OOP는 최대 4GB(= 2^32bit), 64bit에서는 18.5EB(= 2^64bit)까지 쓸 수 있다. 64bit에서는 포인터의 크기가 4 -> 8바이트로 두 배가 되어 포인터 자체가 차지하는 메모리와 캐시 공간이 많이 늘어난다. 물리적(한 서버에 EB 단위까지 메모리가 증설되는 것은 사실상 불가능)인 관점에서나 논리적(Heap 크기가 크면 미사용 객체의 참조를 해제하는 GC 과정에서 STW가 너무 길어짐)인 관점에서 많은 64bit 가상머신에서는 포인터 압축을 통해 32bit의 OOP를 이용하고 있다.
- 물론 (32bit OOP의) 4GB짜리 Heap은 운영 환경의 워크로드에는 역부족이다. 때문에 객체 그 자체를 참조하는 것이 아닌, 객체의 offset을 참조하는 Compressed OOP 방식을 사용한다. 즉, 64bit 기반 JVM이 OOP는 32bit 기반으로 유지하면서, 4GB 이상의 Heap 영역을 갖도록 만든 것이다. 만약 32GB 이상 Heap을 설정하면 JVM은 자동으로 다시 Native OOP(64비트 참조) 로 변경됩니다. CPU는 메모리에서 데이터를 읽을 때 버스를 통해 특정 크기의 덩어리(block)로 로드한다. 이때 일반적인 Cache Line이 8개의 8바이트 크기로 이루어지므로, JVM 역시 객체를 8바이트 단위로 정렬한다. (객체 주소가 8바이트 정렬되어 있으므로, offset은 항상 8의 배수) 32비트 정수로 표현 가능한 최대 값은 2^32−1입니다. 여기서 offset에 8을 곱하면 최대 32GB(= 2^32×8)까지 표현 가능하다.
2. HNSW (Hierarchical Navigable Small World)
대부분의 VectorDB들은 모두 임베딩 벡터를 저장함에 있어, KNN의 엄청난 계산량을 감당하기보다는 Approximate하게 근접 이웃을 찾아내고 있는데, Graph 이론 기반의 HNSW 알고리즘이 대표적이다. (HNSW 구현체로는 Faiss가 있음)
- 전통적인 자료구조(kd-tree나 ball-tree) 기반의 방법은 저차원에서는 우수한 성능을 보이지만, 차원의 저주(curse of dimensionality)로 인해 임베딩 벡터와 같이 고차원 데이터를 다룰 때는 성능이 급격히 저하된다. 이에 반해 HNSW(Hierarchical Navigable Small World) 알고리즘은 그래프 이론에서 착안한 ‘Small World’ 네트워크의 특성을 적극 활용하여, 데이터 간의 연결 관계를 다층적인 그래프로 모델링함으로써 탐색의 효율성과 정확도를 동시에 확보한다.
- HNSW 알고리즘은 여러 층(layer)으로 구성된 그래프 구조를 사용한다. 가장 낮은 0층은 모든 데이터를 포함하는 완전한 그래프로 구성되며, 상위 층으로 올라갈수록 점점 적은 노드들이 포함된다. 상위 층들은 근접성에 따라 샘플링된 대표 노드들의 집합으로 구성되며, 전체 데이터셋의 대표성을 띠면서도 탐색 시 초기 진입점 역할을 수행한다. 탐색이 시작되면, 초기에는 상위 층의 노드들 사이에서 대상 벡터와의 거리를 측정하며, 가장 가까운 노드를 찾아낸다. 이후 그 노드를 시작점으로 하위 층에서의 탐색을 진행하는데, 이때 각 노드는 자신의 인접 노드들과 연결되어 있어, 점진적으로 탐색 범위를 좁혀가며 최종적으로 근사 최근접 이웃을 찾게 된다.
* 간단하게 말해보는 감상평
- 자료구조의 단순 설명 나열이 아닌, 하나의 자료구조(ex. 그래프)에서 파생된 또 다른 자료구조(ex. 트리), 그리고 그 자료구조를 활용한 알고리즘(ex. 허프만 코딩)을 이해시키는게 기가 막히다.
- 가장 기본적인 배열과 연결리스트의 장단점을 알려주면서, 원하는 성능을 제공하지 못하면 트리를 사용해야 하는 이유에 대해서도 친절하게 소개한다.
- 알고리즘 코딩 스터디를 하기 전, 개념 잡는데 꼭 참고하면 좋을 책이다.